Running LLMs locally using Ollama. Step-by-Step guide for private Gen AI setup


Generative AI & LLM
Generative AI refers to a category of artificial intelligence models designed to generate new content like text, images, music, etc.
Thanks to ChatGPT, there is a huge surge in interest and discussion around generative AI & Large Language Models(LLMs).
This blog gives you a step-by-step guide for running LLMs locally or on-premises using Ollama and building your own private GenAI interface using OpenWebUI. You can use the steps defined in this blog to add any publically available LLMs to this setup as per your need and as long as your hardware can run.
Why run LLMs locally/on-premise?
Running LLMs locally or on-premises provides greater control, security, and flexibility, making it an attractive option for organizations with specific needs around data privacy, customization, and cost management.
Setup
This part may differ depending on your Operating System & Hardware
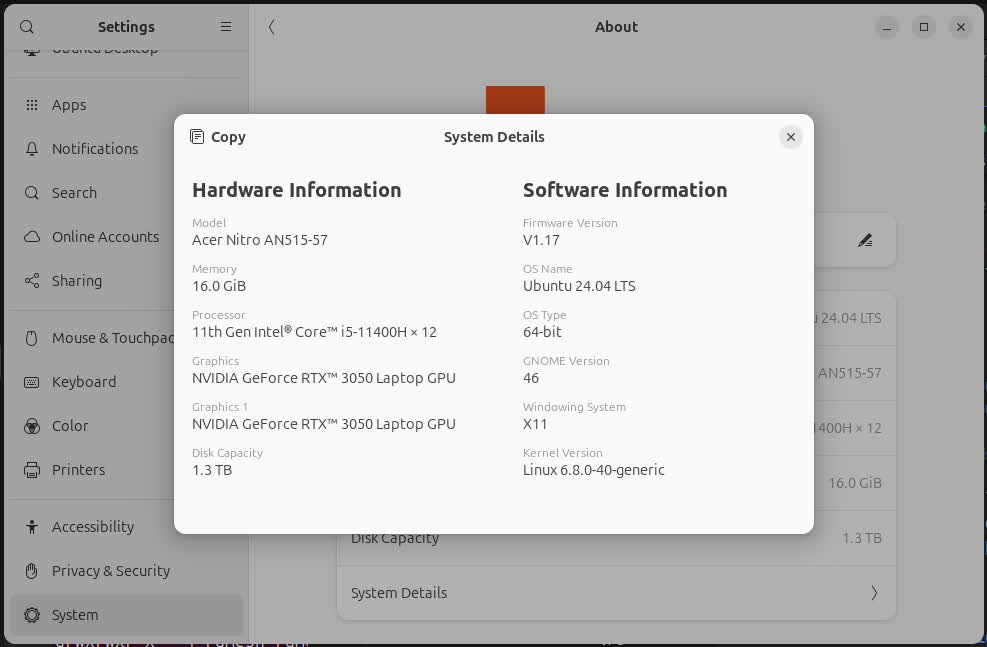
Hardware config
I am using 3-year-old mid-spec gaming laptop, but any modern-day laptop/desktop with decent processors & GPU should be working fine to experiment with.
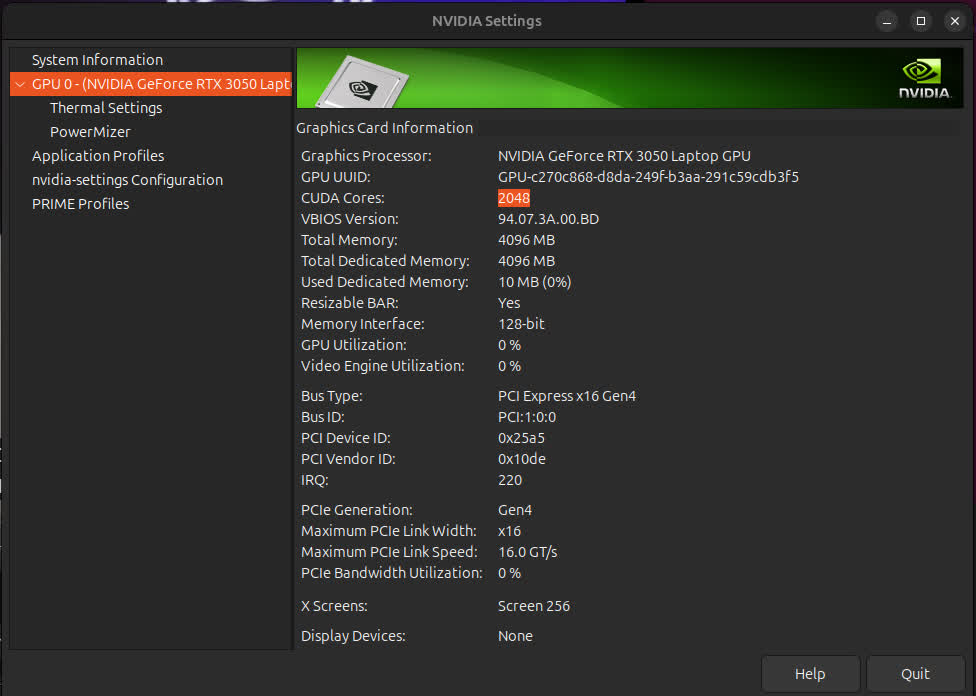
Driver setup
Ollama detects your GPU automatically if it's ready to use, so please ensure you have installed proper GPU drivers.
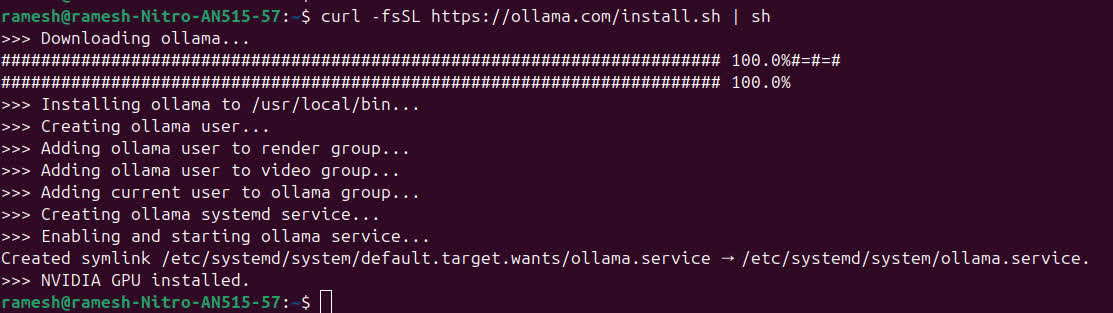
Install Ollama
Go to the Download Ollama page and get installation instructions for your OS.
For Linux, you can use:
curl -fsSL https://ollama.com/install.sh | sh
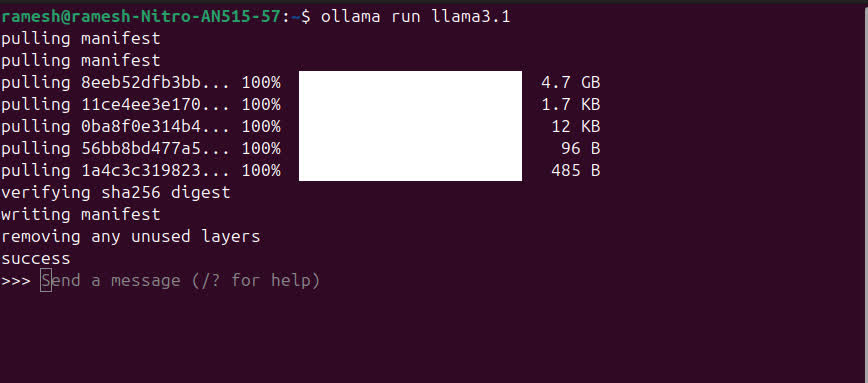
Install LLM
'Ollama Library' has a list of models to choose from. I tried Llama 3.1 by Meta first.
It tries to run a specific model, if it's not found then it downloads the model.
ollama run llama3.1
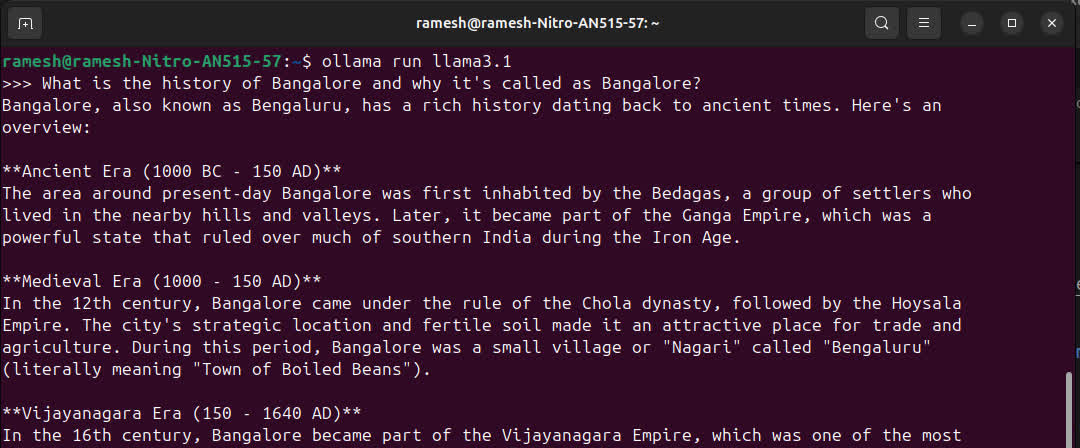
Running the LLM in CLI mode
ollama run ollama3.1 will open up the CLI for the model, and you can interact with it like a normal chatbot.
To exit from the prompt, press Ctrl + d or type /bye.
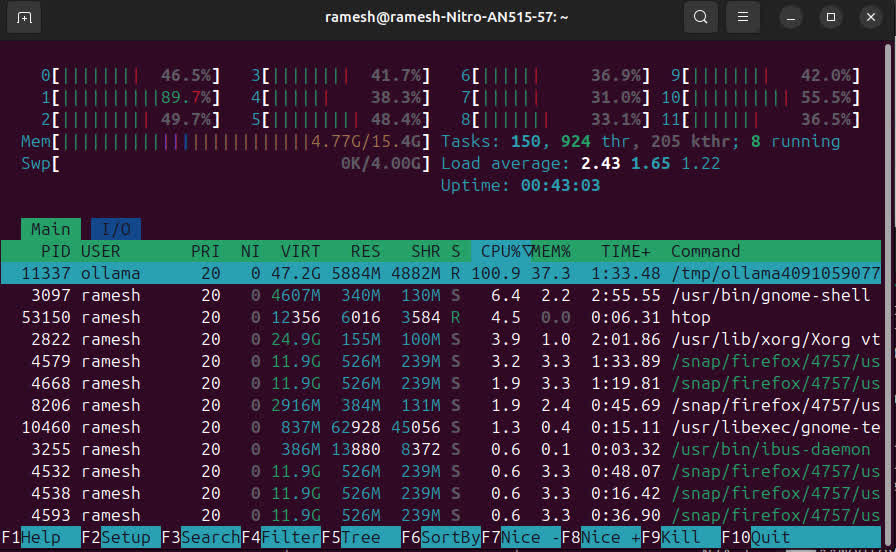
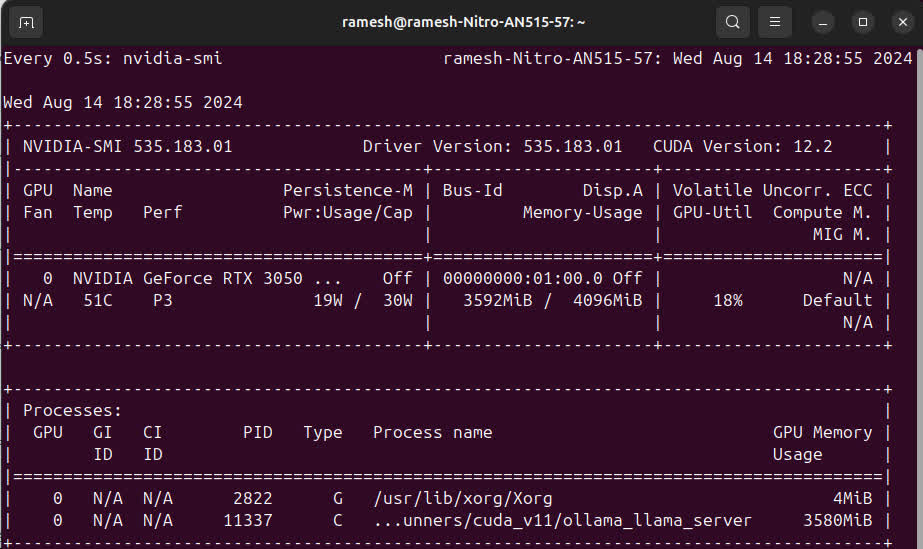
Monitoring resources
Running LLM can be a huge task on the hardware, we can monitor CPU & GPU using htop & watch -n 0.5 nvidia-smi
Setting up web-UI interface
There are a lot of options to choose from here. I chose OpenWebUI
Setup OpenWebUI docker
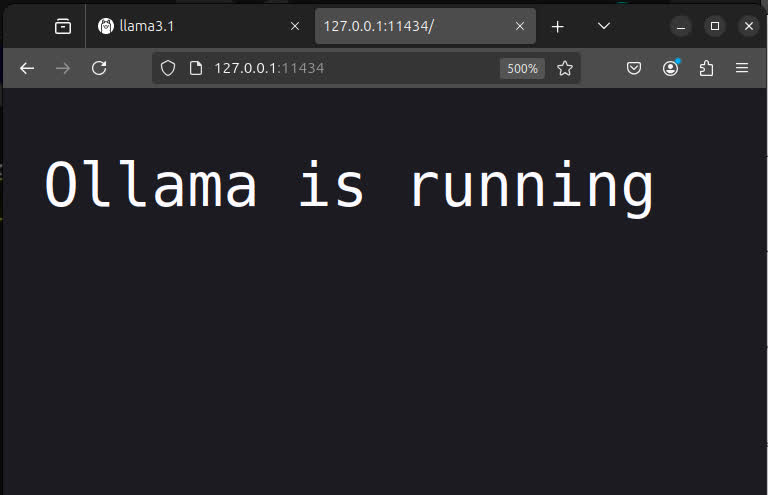
Make sure the Ollama interface running, by opening http://127.0.0.1:11434/
Run OpenWebUI in docker with the next command:
sudo docker run -d --network=host -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
- Open the browser and go to http://localhost:8080/
- Create a new Admin account.
- Start talking to your private LLM.
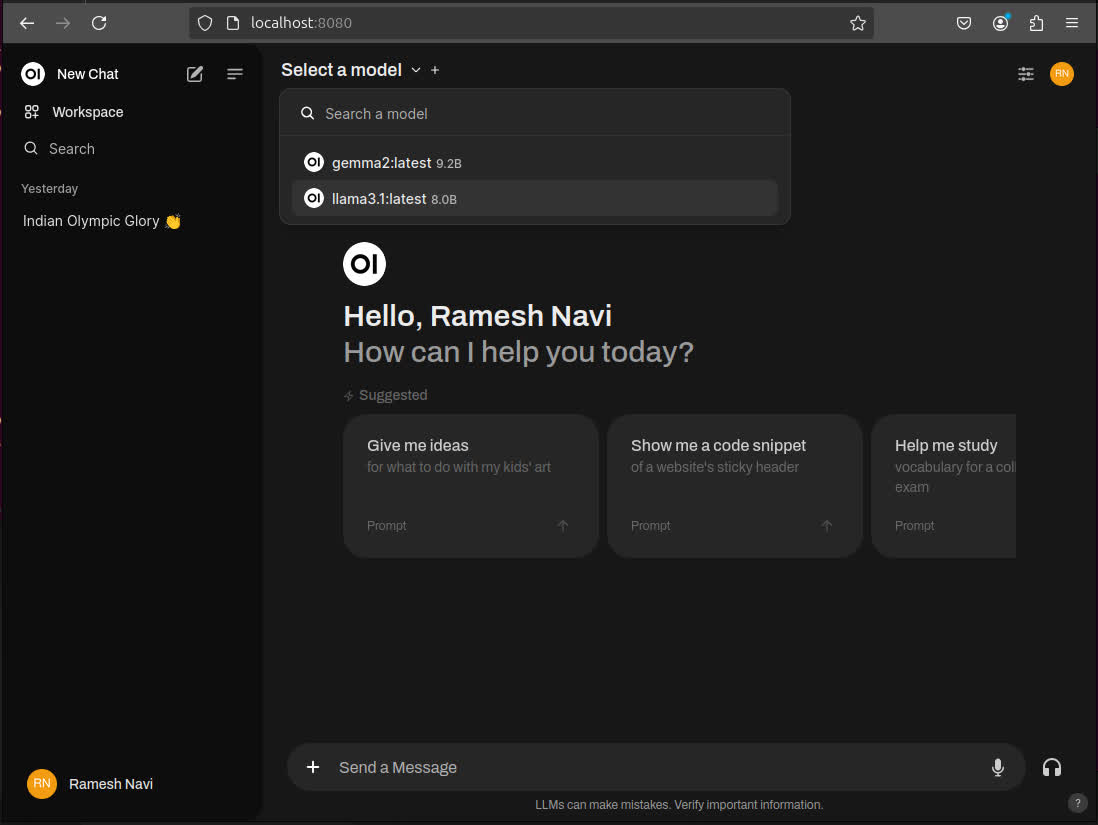
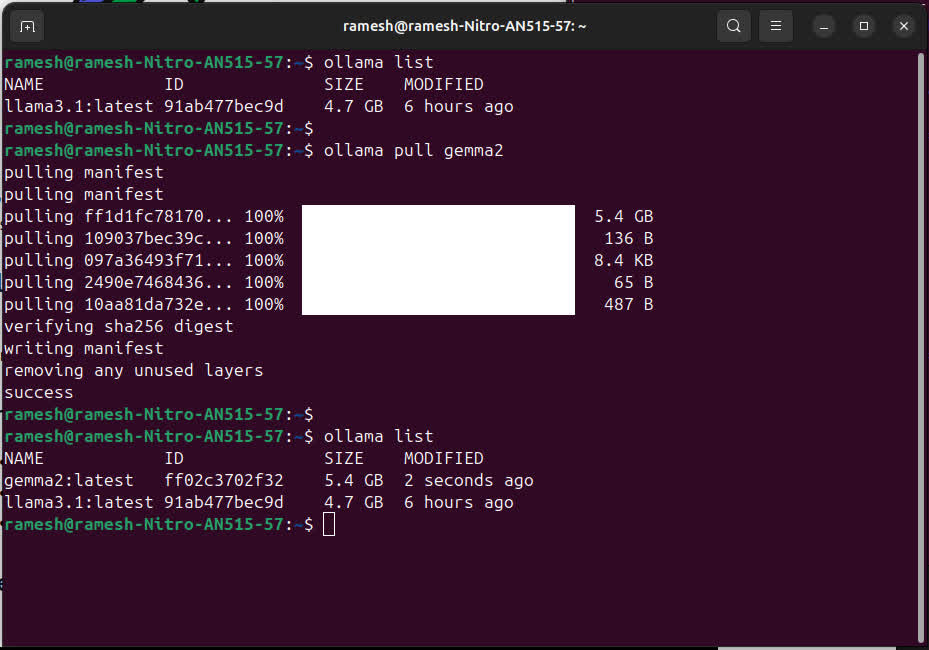
Adding multiple LLMs to Ollama
You can add multiple LLMs to the Ollama setup and you can easily switch between them on OpenWebUI.
I am adding Google Gemma 2.
Conclusion
In conclusion, running Ollama locally not only empowers you with full control over your AI workflows but also ensures that your sensitive data remains secure and private, making it a smart choice for those who prioritize data privacy and autonomy.